For those who might be new to OpenCTI, it's an open-source platform tailored to help organizations efficiently manage their cyber threat intelligence (CTI) knowledge and observables. This platform provides a meticulously structured, organized, and visually accessible repository for both technical and non-technical information concerning cyber threats. To illustrate, imagine all network traffic from your organization to the outside world being captured and stored in OpenCTI as observables, such as IP addresses. Security teams and tools can then analyze these IPs, leveraging enrichment and third-party services to identify any suspicious activity or indicators of compromise. OpenCTI streamlines such tasks, making workflows and use cases more manageable and efficient.
If you're eager to explore further into OpenCTI and its functionalities, you can access the link to the open-source project and its introduction provided here:
OpenCTI Project Introduction
With considerable experience in actively working with OpenCTI, I've witnessed its remarkable growth and increasing prominence, demonstrated by successful fundraising rounds. The OpenCTI blog consistently showcases its significant contributions to combating cybercrime, including notable collaborations with agencies like the FBI, along with impressive achievements in securing substantial funding. Encouraged by these milestones, I'm eager to share a deployment use case that can be applied not only to OpenCTI but also to other platforms in general, emphasizing their high performance and reliability.
Context
For a local deployment, the easiest way is to use Docker Compose, which provides a straightforward setup process.
The detailed steps can be found in this link: OpenCTI Docker Compose.
However, in a production environment, adopting a different approach is essential to ensure the system's high performance, reliability, and resilience.
For this purpose, Kubernetes is the preferred choice due to its scalability, reliability, and ease of management. To streamline the deployment process, Helm Charts are utilized to package and manage Kubernetes applications. This article will guide you through the deployment of OpenCTI using Kubernetes and Helm Charts, ensuring a smooth and efficient setup.
The infrastructure services in this post is based on AWS, but the same approach can be applied to other cloud providers, including Kubernetes alternatives, i.e., Amazon Elastic Container Service (ECS).
Architecture
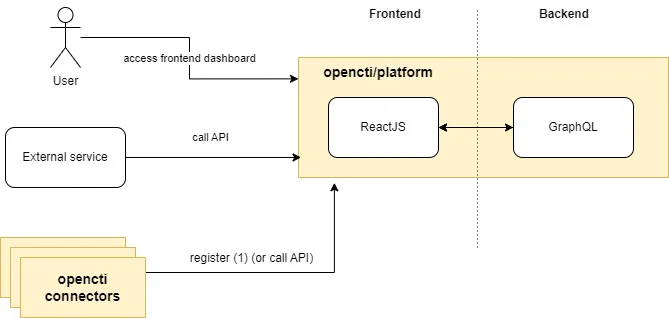
OpenCTI consists of three main components: the Frontend, Backend, and Database.
These are enhanced with additional data services such as a message queue (RabbitMQ), Redis, object storage (MinIO),
and other components like Workers and Connectors to extend data ingestion capacity.
Below is the original architecture of OpenCTI as introduced at OpenCTI Deployment Overview.
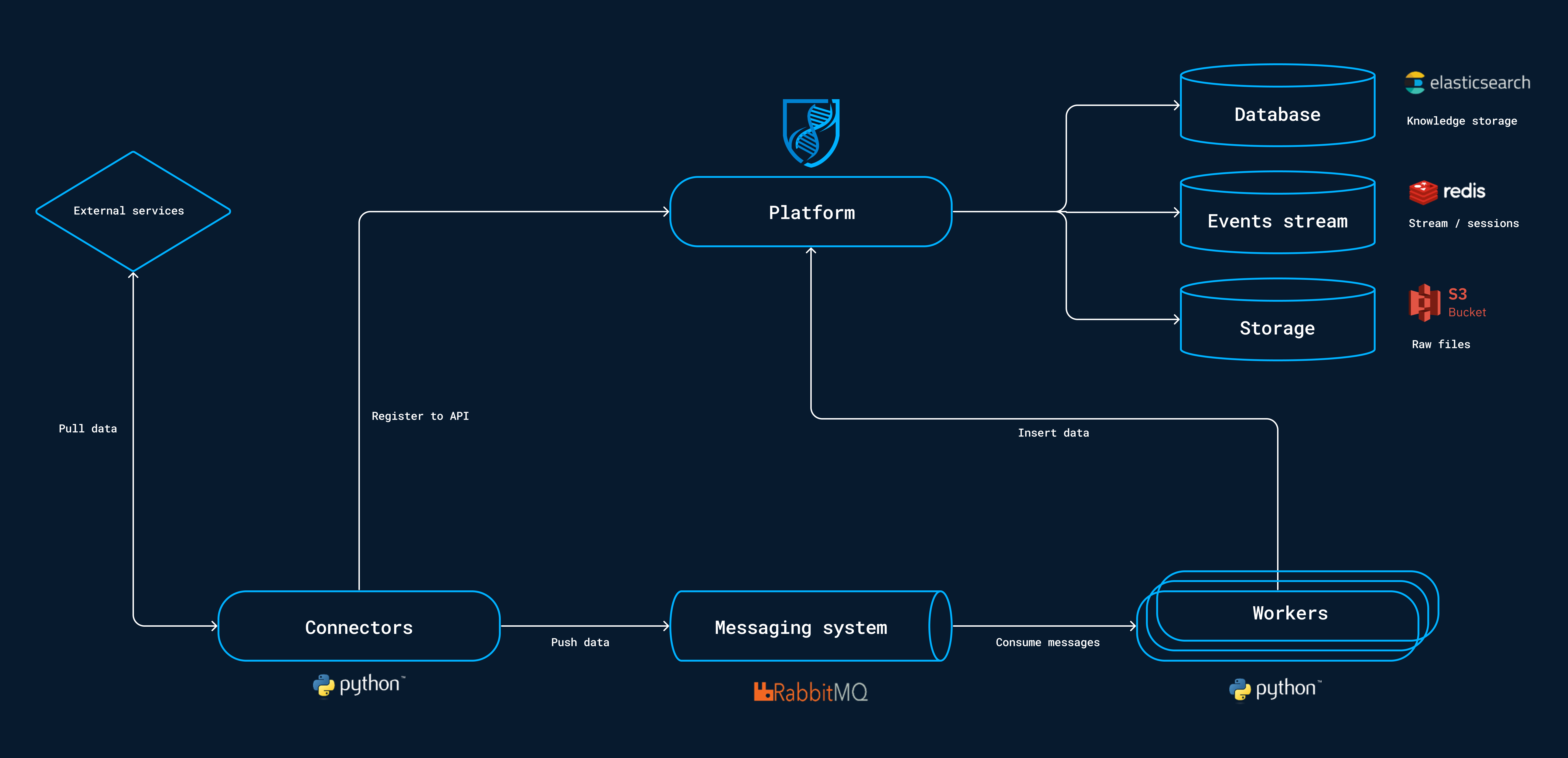
Cloud-based Services
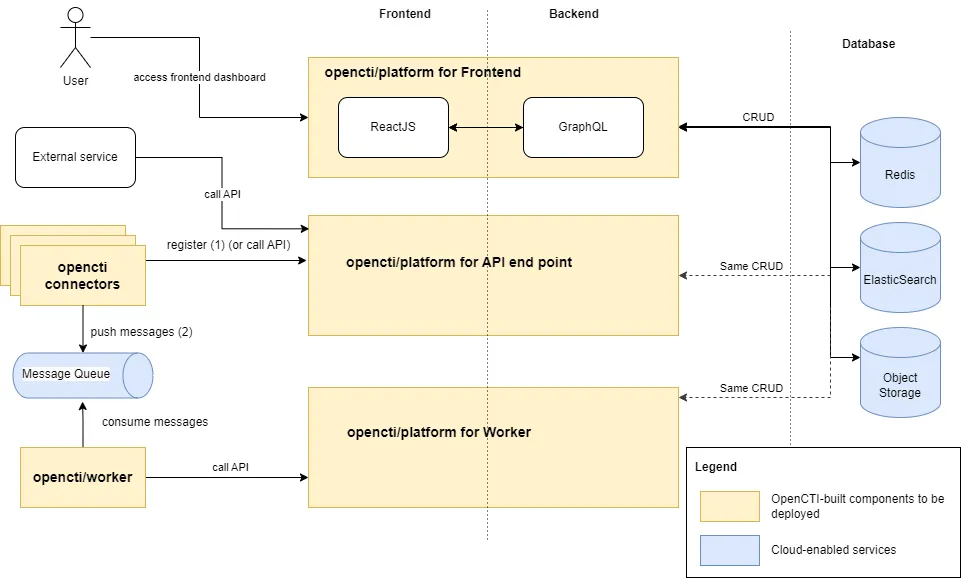
Below I redraw the architecture to highlight components in our deployments.
OpenCTI combines its Frontend and Backend into a single Docker image, opencti/platform.
In the deployments below, I use the pre-built Docker image provided by OpenCTI, instead of modifying the source code or creating new builds myself.
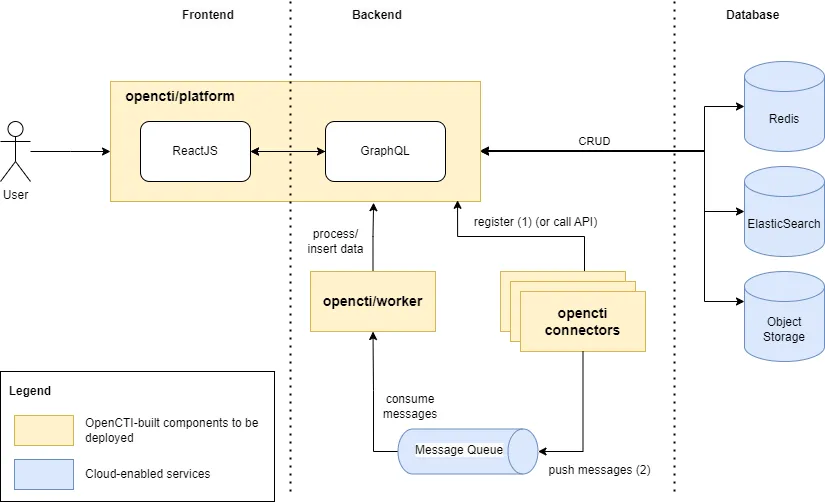
In the architecture above, cloud-based services are utilized to reduce the complexity of the deployment process, allowing us to focus on the main components of OpenCTI: Platform, Workers, and Connectors.
Below is a map of cloud-based services (in blue) to use for a hassle-free deployment process. "N/A" in the table means that the cloud provider does not offer the service directly, so we need to manage the service ourselves, including deployment, scaling, and monitoring. For example:
- To use RabbitMQ in Azure or GCP, we need to deploy RabbitMQ to a computing node, such as GKE or AKS, or simply a VM.
- At the moment, only the S3 interface is supported in OpenCTI. To use MinIO (S3 compatible) in GCP, we can use an interface or client to connect to GCP Cloud Storage, as mentioned in this article: Minio Client.
OpenCTI appears to be more compatible with AWS than other cloud service providers. All components in the OpenCTI platform can be setup in AWS without compatibility concerns.
It is possible to use other cloud providers, but we will need to manage services ourselves (deployment, versioning, backup, restore, etc.).
OpenCTI Deployment Suggestions
The Filigran team suggests the following deployment architecture for OpenCTI, highlighting a few key points:
- The upper part consists of cloud-powered services that are highly available, scalable, and managed by cloud providers.
- There are two clusters of the OpenCTI Platform: one for users and connectors (OpenCTI Frontend Cluster) and the other for workers (OpenCTI Ingestion Cluster).
- Users and connectors are connected to the same OpenCTI platform cluster via a load balancer.
- Every three-worker cluster is connected to an OpenCTI instance.
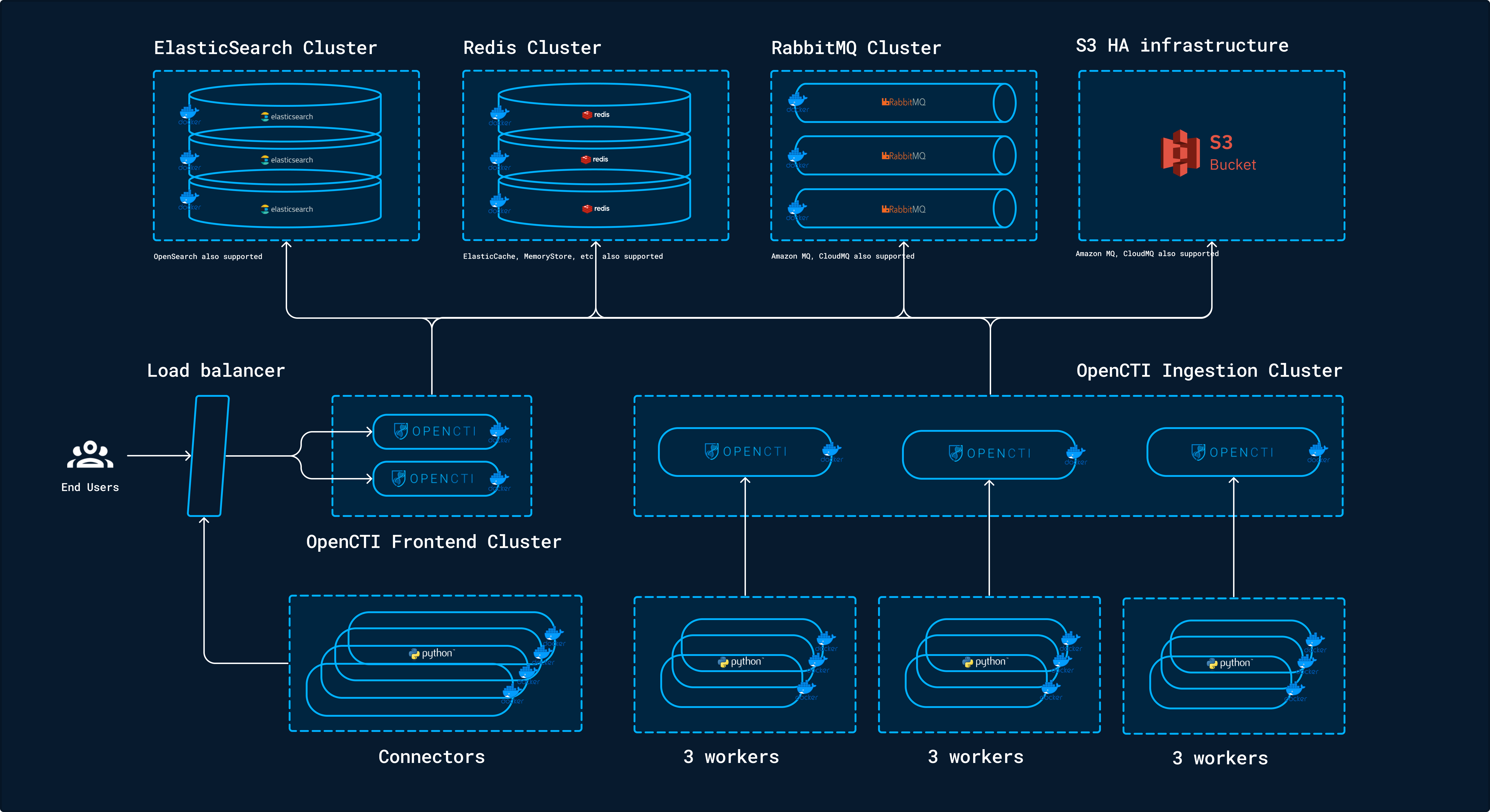 https://docs.opencti.io/6.1.X/deployment/clustering/
https://docs.opencti.io/6.1.X/deployment/clustering/
Overall, it is beneficial to have a separate cluster for the workers platform, as they handle the heavy lifting of ingesting data from the message queue. However, this is not sufficient because connectors also perform heavy lifting tasks that can impact or block the frontend cluster, interrupting the user experience.
In most cases, connectors perform the following tasks:
- Register themselves with the OpenCTI platform.
- Obtain message queues allocated to them.
- Send messages, data fetched from external sources, to the acquired message queue.
This approach ensures that services are decoupled and data are ingested asynchronously. Therefore, avoid bottleneck issue, i.e., to slow down the frontend cluster.
This is how the send_stix2_bundle method is implemented in the pycti library, which is recommended for use when implementing connectors.
Problems
However, in some use cases—which are not rare—when synchronous ingestion in real-time is needed, connectors send messages directly to the OpenCTI platform API endpoint instead of the message queue.
Sharing the same cluster for the frontend and backend work (API calls) in this scenario can make the frontend cluster busy, potentially impacting the user experience.
Solution
Once we understand the problem, we can come up with a solution, which is quite simple: separate the frontend and backend clusters.
- The frontend (OpenCTI platform) cluster is dedicated to users. Its backend
/graphql is only for the frontend. We can configure it to be accessible strictly from the same URL domain as the frontend (for HTTP requests).
- The connector-backend (OpenCTI platform) cluster is for connectors and API calls only. We can assign a separate domain for it, such as
api.your-domain.com that points to api.your-domain.com/graphql, and provide this URL endpoint to connectors.
- The worker-backend (OpenCTI platform) cluster is for workers only. Similar to the connector-backend, this cluster has a URL endpoint provided to workers.
- Connectors can reside in their own cluster.
- Workers can reside in their own cluster.
This approach is actually not as complicated as it may seem. It's primarily a matter of configuration and deployment. However, the benefits are substantial, as it will make the OpenCTI platform more reliable and scalable.
If you have a heavy workload in connectors, you can scale the connectors cluster without impacting the frontend cluster. Similarly, the same applies to the workers cluster.
Deployments
There are many deployment and configuration options, that we can choose from https://docs.opencti.io/6.1.X/deployment/installation/.
Infrastructure
Terraform serves as an excellent option for infrastructure as code (IaC), providing a means to prepare the infrastructure for OpenCTI.
Alternatively, for AWS users, CloudFormation can be employed. Tools like Troposphere can aid in generating CloudFormation templates.
Below are examples of components that can be prepared with IaC in AWS:
| AWS IaC | Main component | Additional component | Note |
|---|
| Database | OpenSearch | S3 bucket, IAM user, IAM role | In some use cases, you may find yourself to create manual snapshot of the database (stored in an S3 bucket), i.e., before a major upgrade, to restore back to the point before an upgrade deployment. |
| Object Storage | S3 | Backup Vault and Plan, IAM user, IAM role | To backup S3, we can create a Backup Vault, Backup Plan, and related IAM users and roles (Backup, Restore, OpenCTI credential access/role) |
| Cache/Feed Event | ElastiCache Redis Cluster | | |
| Message Queue | AmazonMQ RabbitMQ engine | | |
| Kubernetes cluster | EKS | | |
| Networking | Security group, Route53 | | |
| Monitoring | CloudWatch | Metrics, Alarm | |
| Secrets | AWS Secrets, ParameterStore | | To generate and share opencti admin credentials, opensearch, s3, rabbitmq credentials, etc. in Deployment's environment variables |
Deployment
Kubernetes Helm Charts offer a robust choice for deploying OpenCTI. An example of the Helm chart deployment can be found here: OpenCTI Server Helm Chart.
In Kubernetes, the internal Load Balancer can be optimized with proper configurations of readiness probe and liveness probe. Once you determine the optimal number of replicas, readiness and liveness probes for your OpenCTI deployment, which may differ from the default configuration, you can achieve a stable and reliable OpenCTI platform.
Below is a helpful article to read about Load Balancers in Kubernetes: Kubernetes Load Balancer Configuration.
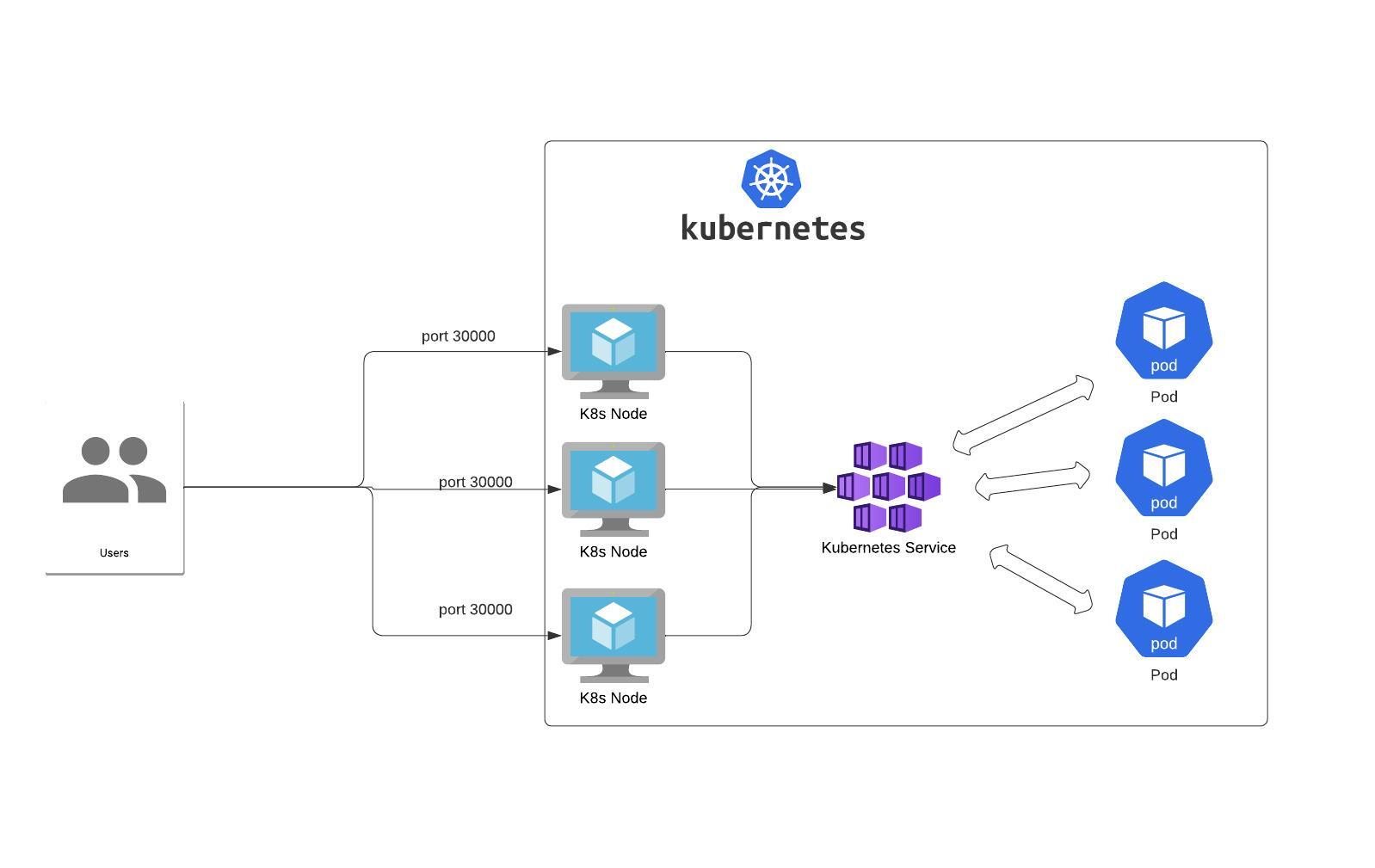 https://cast.ai/blog/kubernetes-load-balancer-expert-guide-with-examples/#What%20Is%20A%20Kubernetes%20Load%20Balancer?
https://cast.ai/blog/kubernetes-load-balancer-expert-guide-with-examples/#What%20Is%20A%20Kubernetes%20Load%20Balancer?
Below is a sample deployment configuration for OpenCTI using Helm Charts, which you'll need to adjust to fit your own environment, including the number of replicas (pods), readiness probe, liveness probe, etc.
In this deployment:
- The number of worker replicas is set to three times the number of worker-platform replicas, following the recommendation in the OpenCTI documentation.
- Workers are configured to wait until the worker-platform is ready before starting deployment (initContainers). This ensures that workers can connect to the worker-platform. Failing to wait could lead to deployment failures in your CI/CD pipeline, trigger false alarms, or result in the recreation of pods multiple times.
# Sample OpenCTI deployment configuration using Helm Charts
# Adjust the following parameters based on your environment
opencti:
replicas: 2
image: opencti/platform
readinessProbe:
# Configure readiness probe settings
livenessProbe:
# Configure liveness probe settings
worker-platform:
replicas: 2
image: opencti/platform
readinessProbe:
# Configure readiness probe settings
livenessProbe:
# Configure liveness probe settings
worker:
replicas: 6
image: opencti/worker
initContainers:
# Configure workers to wait for worker-platform ready
| Deployment/Service/Ingres | Container Image | Replicas | container environment | spec |
|---|
| UI | opencti/platform | 2 | OpenID/SAML/Auth0 for authentication | |
| Connector-platform | opencti/platform | 2 | no user authentication required | |
| Worker-platform | opencti/platform | 2 | no user authentication required | |
| Workers | opencti/worker | 6 | OPENCTI_URL = Worker-platform | initContainers to wait for Worker-platform deployed, before start deploying Worker. |
| Connectors | https://github.com/OpenCTI-Platform/connectors | 1 or N | OPENCTI_URL = Connector-platform | |
Conclusion
Finding a one-size-fits-all solution for OpenCTI deployment can be challenging, as it depends on various factors such as the use case, environment, and available resources. However, in many cases, separating the frontend and backend clusters is a recommended practice, not only for OpenCTI and Threat Intelligence Platforms but for any platform, as it enhances reliability and scalability.
Essentially, frontend and backend are just names of services that interact to build a more complex system. Understanding the dependencies and managing them effectively is crucial for ensuring system reliability and scalability.
Some techniques outlined in this article to manage dependencies include:
- Decoupling services: separating frontend, backend, workers, and connectors.
- Implementing asynchronous batch ingestion: involving connectors, workers, and message queues.
- Leveraging cloud-based services: utilizing highly available and scalable services managed by cloud providers to reduce operational complexity, including scaling, backup, restore, and monitoring.
- Utilizing load balancers, replicas, readiness probes, liveness probes, etc.
- Implementing caching mechanisms.
- And more.
By adopting these techniques, you can build a more resilient and scalable OpenCTI deployment tailored to your specific needs and environment.

